

About#
Nublado is a Kubernetes installation of JupyterHub with custom authentication and lab spawner implementations and supported by the Nublado controller.
Nublado is designed for deployment using Phalanx. Deployment outside of Phalanx is theoretically possible but is not supported. Other Phalanx components, such as Gafaelfawr, are required for Nublado to work correctly.
Architecture overview#
A Nublado deployment consists of the JupyterHub pod, its associated proxy server pod, and a Nublado controller pod, plus their supporting Kubernetes resources. JupyterHub and its proxy server are installed using the Zero to JupyterHub Helm chart as a subchart of the Nublado Phalanx application.
The JupyterHub Docker image is the same as the normal JupyterHub image, with the addition of a custom spawner module and a custom authenticator module. The Nublado controller image is a standalone Python service built from the Nublado repository. Both the JupyterHub and the Nublado controller images are built from the Nublado source tree by GitHub Actions. The proxy server image is the standard proxy server provided by Zero to JupyterHub.
Rather than have JupyterHub create user lab pods directly, as is typical in most JupyterHub Kubernetes installations, all Kubernetes operations are done by the Nublado controller, and it is the only component with extra Kubernetes privileges. JupyterHub spawns and deletes user labs by sending REST API requests to the Nublado controller. The controller is also responsible for constructing the spawner form for the JupyterHub API and for nearly all aspects of lab configuration.
To supplement the JupyterLab interface, which only allows simple file upload and download into the user’s home file space, the Nublado controller can optionally also create WebDAV file servers for the user that mount the same file systems that user lab pods mount. This allows users to use the WebDAV clients built into most operating systems to more readily copy files to and from the file space underlying their lab.
There is additionally a mechanism to allow starting and stopping of an administrative file server.
This can be useful if a user’s files are owned by the wrong user, or to investigate out-of-storage-quota complaints and determine what directories are causing the problem.
This is not exposed via WebDAV or any Ingresses; rather, an administrator is expected to spawn an administrative file server and connect to it with kubectl exec.
Since the lab images used by Rubin Observatory are quite large and pulling an image can therefore take a considerable amount of time, the Nublado controller prepulls a configured set of images on every cluster node. This set of images is the same as those available as radio button (not dropdown) options in the user-facing spawner form.
JupyterHub, its associated proxy, and its configuration and supporting Kubernetes objects other than its secret and ingress are installed using the Zero to JupyterHub Helm chart as a subchart. The Nublado controller, its configuration, the JupyterHub secret and configuration, and the ingress for the proxy are managed directly by Phalanx.
Component diagrams#
Overview#
Here is an architectural diagram showing the high-level Nublado components.
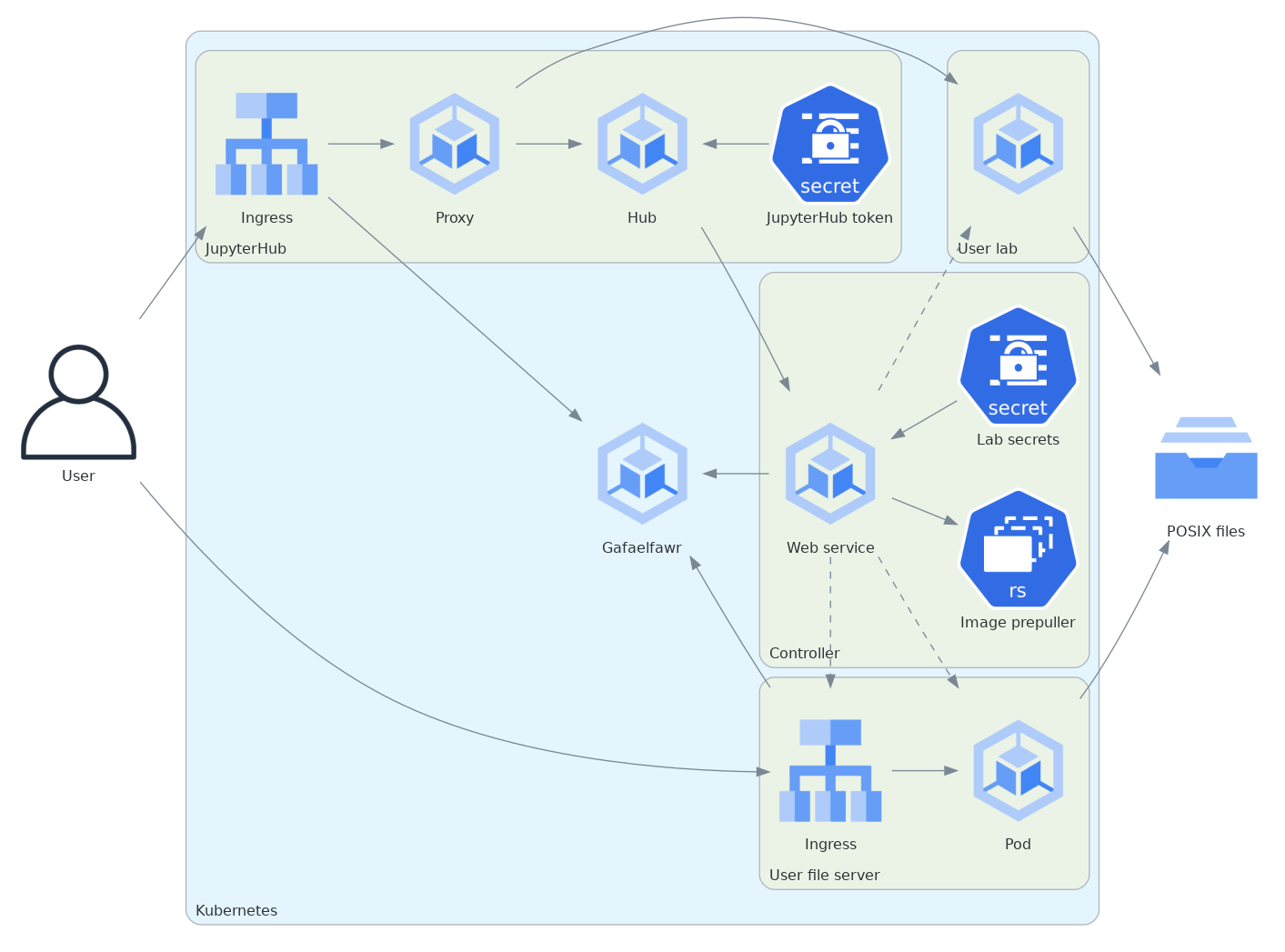
Solid lines show the path of API communication. Dashed lines show components that are created by other components.
This diagram collapses the user’s lab and file server into a single box to show their relationships with other components more clearly.
Not shown here is that the Ingress resource is created with a GafaelfawrIngress custom resource so that access to the file server is protected by Gafaelfawr authentication and access control.
User lab#
Here is more detail showing a user’s lab environment, omitting JupyterHub and the Nublado controller.

Storage configuration will vary by environment and may involve any of NFS, host file systems on nodes, or PersistentVolumeClaim and PersistentVolume pairs.
User file server#
Here is more detail showing a user’s file server, omitting the other components:

Not shown here is that the Ingress resource is created with a GafaelfawrIngress custom resource so that access to the file server is protected by Gafaelfawr, similar to the JupyterHub Ingress.
Administrative file server#
Here is more detail showing the administrative file server, omitting the other components:
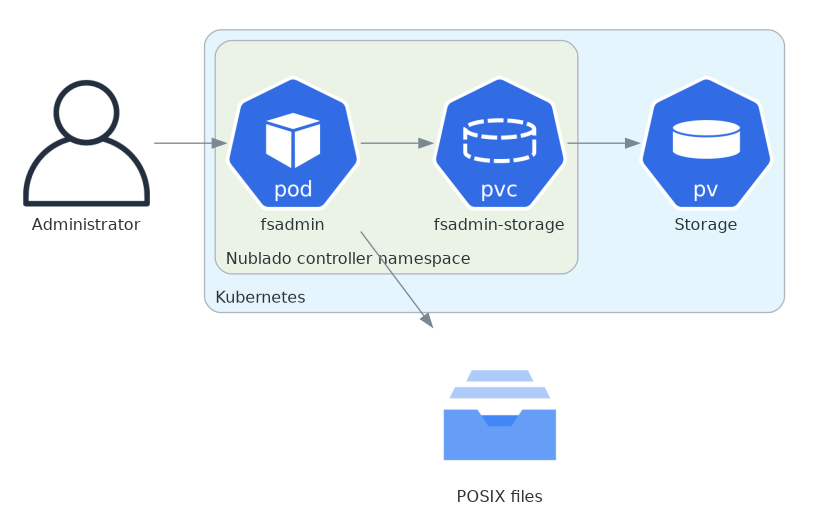
Note that there are no Ingresses connecting the administrative file server to the network.
An administrative user is expected to have access to kubectl exec in order to access the administrative file server.
Sequence diagrams#
Lab spawning#
Here is a sequence diagram showing the operations involved in spawning a user lab:
sequenceDiagram
browser->>+hub: GET /nb/hub/spawn
hub->>+controller: GET labs/<username>
controller-->>-hub: 404
hub->>+controller: GET lab-form/<username>
controller-->>-hub: partial spawn page
hub-->>-browser: spawn page
browser->>+hub: POST /nb/hub/spawn
hub->>+controller: POST labs/<username>/spawn
controller-->>hub: 201
controller->>+kubernetes: create resources
controller-)kubernetes: watch events
controller-)kubernetes: watch pod status
hub->>controller: GET labs/<username>/events
controller--)hub: spawning events
create participant lab
kubernetes->lab: create lab pod
kubernetes--)-controller: lab started
controller-->>-hub: 200
hub->>+lab: wait for lab start
lab-->>-hub: lab started
hub-->>-browser: redirect to lab
Spawn lab#
When the user exits the lab, an extension built into the lab images for the Rubin Science Platform tells JupyterHub to delete the lab. JupyterHub then asks the controller to delete the lab, which then asks Kubernetes to delete the lab and the namespace.
File server creation#
Here is a sequence diagram for creating a user file server:
sequenceDiagram
participant webdav
participant browser
participant controller
participant kubernetes
browser->>+controller: GET /files
controller->>+kubernetes: create resources
controller-)kubernetes: watch pod status
create participant fileserver
kubernetes->fileserver: create pod
kubernetes--)-controller: pod started
controller-->>-browser: 200
webdav->>+fileserver: WebDAV request
fileserver-->>-webdav: WebDAV response
Create file server#
File servers last for as long as they are used. After a configurable idle period, the file server exits. The controller watches for pod exit and deletes the associated file server resources.